Introduction
Even though the hard disks are monitored via S.M.A.R.T. and the status of the ZFS pools is reported regularly with the periodic scripts, there is still no immediate notification in the event that one of the ZFS pools has a problem. So if any ZFS-specific problem occurs, we would like to know immediately. There is a small script for this and extension of the Monit configuration.
NEW: For the very impatient I have a console only section. There are only commands, no explanations.
Last update:
- 15.12.2024: Script adjusted: More details added, formatting corrected
- 24.11.2024: Initial document.
Basic requirements
ZFS
I drew inspiration for this script from the following sources
- https://pawelrychlicki.pl/Article/Details/58/zfs-health-check-script-for-monit-0905
- https://calomel.org/zfs_health_check_script.html
The resulting script is a very lean modification with the following changes:
- Dynamised, one loop for all ZFS pools and actions
ScrubandTrimhave been removed as these are already handled by the periodic scripts- E-mail sent Monit
Firstly, the following additional check is added at the bottom with ee /usr/local/etc/monitrc:
check program zfs_health with path "/root/zfs_health_check.sh"
if status != 0 then alertThe script stored there is created with ee /root/zfs_health_check.sh and the following content:
#! /bin/sh
/usr/bin/printf "%s----------\n"
/usr/bin/printf "%s\n"
/usr/bin/printf "%s\n\n" "$(/sbin/zpool list -o name,size,allocated,free,capacity,health)"
ERROR_DETAILS=""
MISSING_DETAILS=""
LISTPOOLS="$(/sbin/zpool list -H -o name)"
for POOL in ${LISTPOOLS}; do
HEALTH="$(/sbin/zpool list -H -o health ${POOL})"
ERROR="$(/sbin/zpool status ${POOL} | grep errors: | awk '{print $2}')"
if [ "${HEALTH}" != "ONLINE" ]; then
ERROR_DETAILS="${ERROR_DETAILS} ${POOL}: Zustand ist ${HEALTH} (erwartet: ONLINE)"
fi
if [ "${ERROR}" != "No" ]; then
ERROR_DETAILS="${ERROR_DETAILS} ${POOL}: Fehlerstatus ist ${ERROR} (erwartet: No)"
fi
done
if [ -n "${ERROR_DETAILS}" ]; then
MISSING_DETAILS="$(/sbin/zpool status -x -e)"
/usr/bin/printf "%s\n" "${MISSING_DETAILS}"
exit 1
else
exit 0
fiFinally, make it executable with chmod +x /root/zfs_health_check.sh and restart Monit with service monit restart.
If an error occurs, Monit will then send an e-mail with the details of the error and the affected ZFS pool.
The script can also be executed manually:
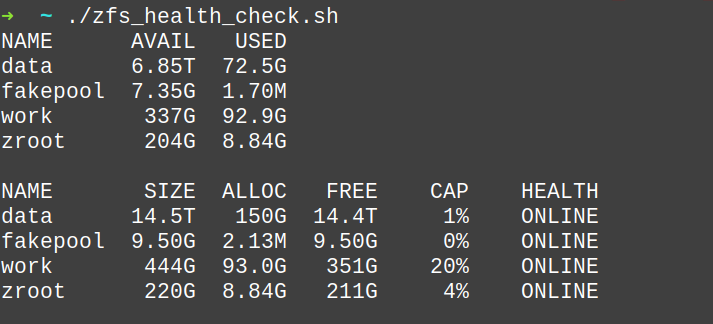
Test
- Remove a hard disc from the
fakepoolwithzpool offline fakepool /poolfiles/file1:- Monit then sends an alarm by e-mail
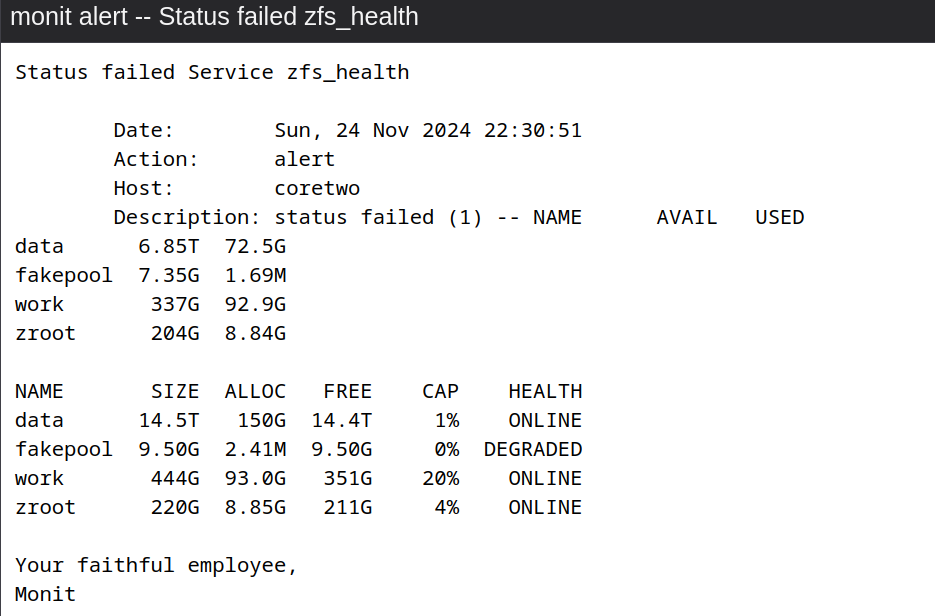
- Monit then sends an alarm by e-mail
- Add the hard drive back to the
fakepoolwithzpool online fakepool /poolfiles/file1:- Monit then sends an all-clear by e-mail
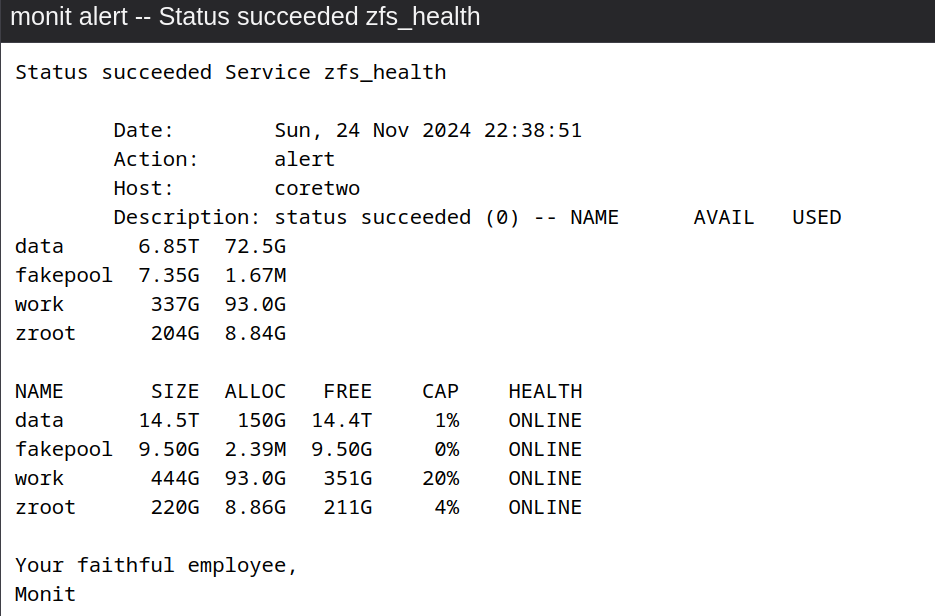
- Monit then sends an all-clear by e-mail
Console
Voilá